The Problem: Too Much to Read. No Idea What Matters.
Every serious UPSC aspirant knows the feeling. Hundreds of sources. Thousands of articles every month. Eight subjects spanning nearly every domain of human knowledge. And an exam that appears to pull its questions from thin air.
The conventional wisdom has always been: read everything, trust nothing. Coaching institutes publish their ‘important topics’ lists based on expert intuition. Most aspirants end up spending months over-preparing on low-probability topics while the questions that actually appear catch them off guard.
The exam feels random because preparation is random, not because the exam actually is.
We decided to find out whether that assumption holds up when you put real data behind it.
The Hypothesis: Patterns Exist. Patterns Can Be Learned.
Look carefully at previous year questions alongside the news that preceded them and something becomes clear. UPSC does not select questions randomly. Certain categories of events, such as Supreme Court judgments, new statutory bodies, international treaty ratifications, major government reports, and named policy schemes, reliably produce exam questions. Others never do, year after year.
Our hypothesis: if current affairs data and historical exam patterns are analyzed at sufficient scale, it becomes possible to identify high-probability topics before the examination.
We built a system to test this. Then we backtested it on six years of actual papers.
What We Built: Almost a Decade of Signals, One Trained System
- 1.5 million+ articles from PIB, The Hindu, Indian Express, Down to Earth, and PRS India, going back to 2011. Automatically filtered for UPSC relevance. Entertainment, sports, and local crime dropped. What remains maps to the exam syllabus.
- 9 years of UPSC Prelims papers (2011–2019) - for training, fully mapped across all eight subjects.
- 7,000+ verified news-to-question links, the training signal that shows the model which kinds of events become exam questions and which do not.
- A state-of-the-art embedding model that understands meaning, not just keywords. An article about a Wildlife Protection Act amendment gets correctly linked to a PYQ about Schedule I species, even when the two share no exact wording.
The model was trained using a strict time-aware methodology, and it was never permitted to see future exam years during training. Each topic is scored on two dimensions: whether it falls within UPSC’s scope and how important it is relative to other signals this cycle.
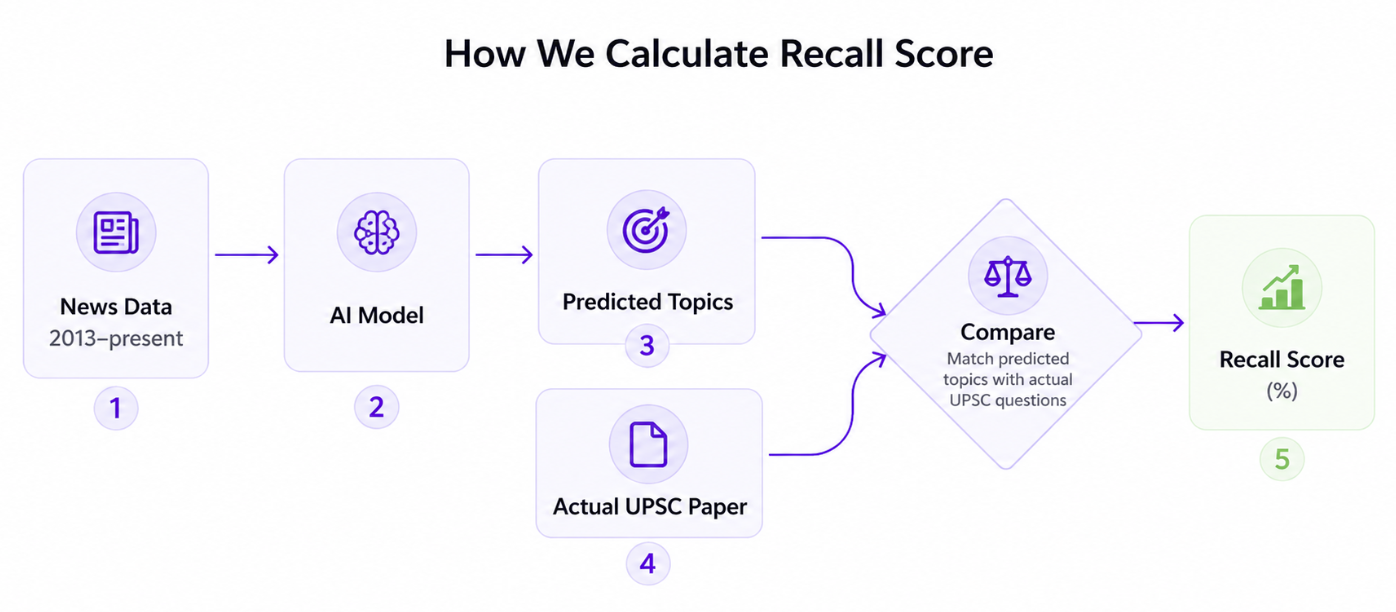
How We Tested It: Six Years of Blind Predictions
Backtesting works exactly like benchmark evaluation for AI models: train on the past, predict the future, measure the gap. For each year from 2020 to 2025:
- The model was trained using only data available before that year’s examination
- A full predicted topic list was generated for that year
- Predictions were compared against the actual UPSC Prelims paper
- Recall (how many real exam topics we caught) was recorded
No data leakage. No hindsight. Each year evaluated as a genuine blind prediction.
Results: Consistent, Measurable Signal Across Six Years
Overall Recall
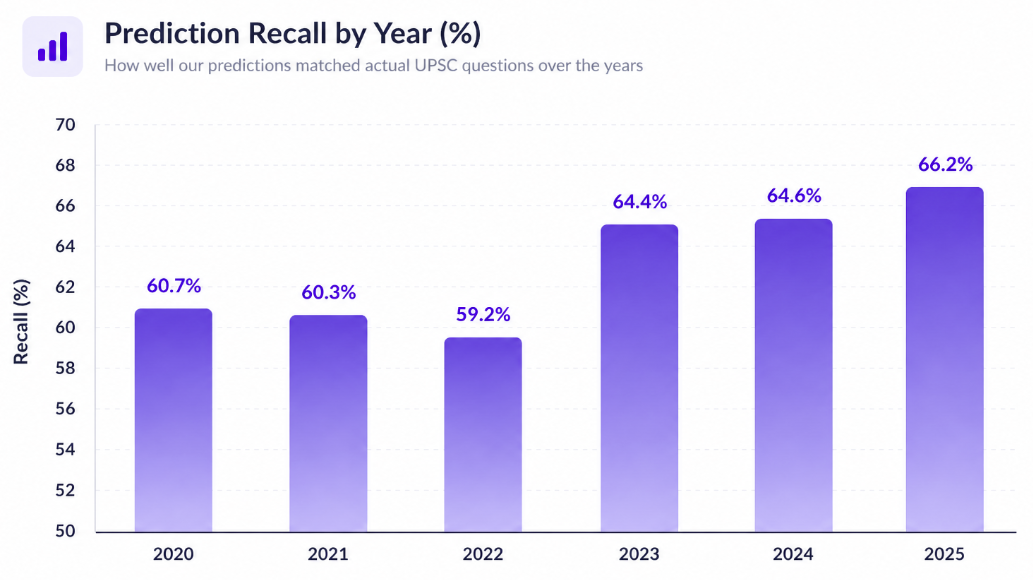
The system recalled an average of 62.6% of actual exam topics across all six years, roughly three out of every five topics that appeared on the actual paper were identified in advance. Performance trended upward, peaking at 66.3% in 2025.
| Year | News Window | Topics Tested | Hits | Recall |
|---|---|---|---|---|
| 2020 | 2018–19 | 84 | 51 | 60.7% |
| 2021 | 2019–20 | 78 | 47 | 60.3% |
| 2022 | 2020–21 | 81 | 48 | 59.3% |
| 2023 | 2021–22 | 76 | 49 | 64.5% |
| 2024 | 2022–23 | 82 | 53 | 64.6% |
| 2025 | 2023–24 | 83 | 55 | 66.3% |
| Avg | 62.6% |
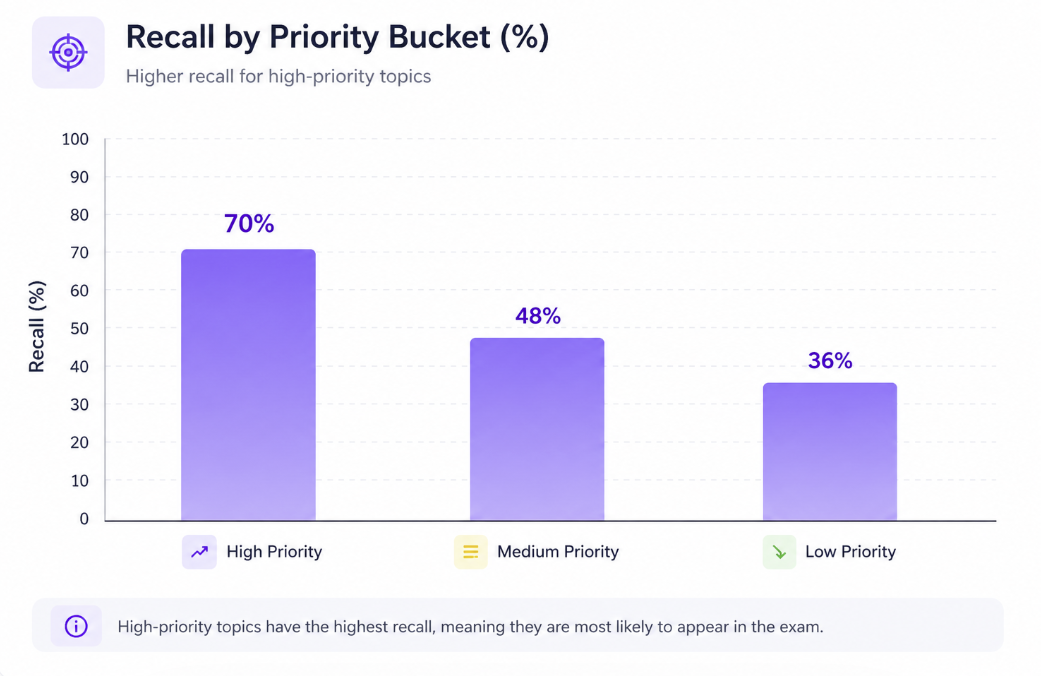
Priority Bucket Performance
| Priority | Topics | Recall |
|---|---|---|
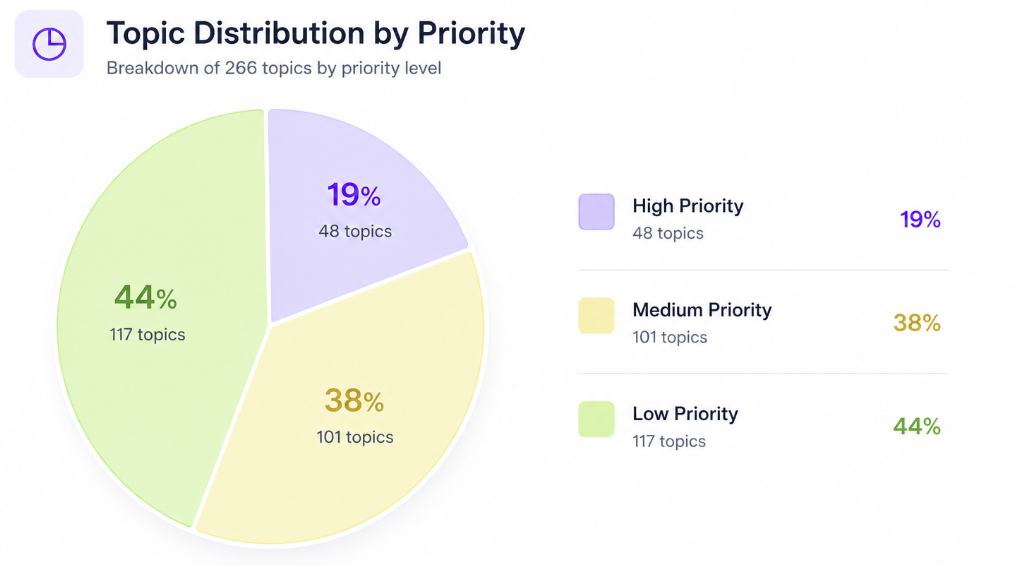
| High | ~50 | ~70% |
| Medium | ~100 | ~48% |
| Low | ~116 | ~37% |
Subject-Level Performance
| Subject | Avg Recall |
|---|---|
| Indian Economy | 92% |
| Environment | 79% |
| Indian Polity | 73% |
| World Affairs | 68% |
| Science & Technology | 66% |
| Geography | 44% |
| Modern History | 35% |
| Art & Culture | 26% |
| Ancient & Medieval History | 15% |
Subjects anchored in current institutional and policy developments are highly predictable. Subjects dominated by static historical knowledge are structurally resistant to news-based prediction, and we are transparent about that.
Sample Confirmed Predictions
| Year | Recall | Confirmed Hits |
|---|---|---|
| 2020 | 60.7% | MPLADS, Tiger Census, Agri Ordinances, WTI crash, Locust swarms |
| 2021 | 60.3% | G-SAP, IT Rules, Economic Survey, Social Security Code, Deep Ocean Mission |
| 2022 | 59.3% | Russia-Ukraine geography, RBI rate hike, WHO Air Quality Guidelines, UNESCO (Hoysalas, Garba) |
| 2023 | 64.5% | Kesavananda 50th, Green Hydrogen, BBNJ Treaty, CBD GBF, CBDC |
| 2024 | 64.6% | PM Surya Ghar, Women’s Reservation, Red Sea crisis, Hoysalas UNESCO, NISAR |
| 2025 | 66.3% | SpaDeX, AI Action Summit, Kavach, COP29 Article 6, BIMSTEC, Periyar, Poona Pact |
One example in detail: The AI Action Summit (Paris, February 2026) was identified 135 days before the 2025 exam, with the correct institutional lineage (Bletchley → Seoul → Paris) and the precise distractor format UPSC used. The actual question tested a false attribution to AWS/Amazon, exactly the trap the system flagged.
Before EdMe vs. After EdMe

| Without Predictions | With EdMe Predictions |
|---|---|
| 10,000+ pages of current affairs | 266 high-signal topics |
| No clear direction | Ranked by confidence level |
| Studying based on intuition | Studying based on 13 years of data |
| Anxiety about missing key topics | Focus on what the data says matters |
What This Means for How You Prepare
The data points toward a fundamentally different preparation strategy.
Focus over breadth. Allocate time toward high-probability topics rather than exhaustive syllabus coverage. The data shows clearly which subjects and topic categories carry signal.
Signal over noise. Current affairs preparation should concentrate on institutional and policy-level developments, such as new bodies, court judgments, treaty ratifications, and government reports. Not general news consumption.
Efficiency over volume. Targeted, data-backed preparation achieves better results with significantly less time. Let the analysis do the filtering. You do the studying.
For UPSC Prelims 2026, the EdMe engine produced 266 prediction topics across all eight subjects, translating to 792 UPSC-format MCQs, each with distractors, a correct answer, and a detailed explanation.
An Honest Note
EdMe’s predictions are not guarantees. They are directional signals based on measurable patterns in data. UPSC remains a rigorous examination that rewards deep understanding, not just topic coverage. Our system does not predict exact questions. It identifies which topics are most likely to matter, so your study time goes where it counts.
Conclusion
Even in an examination widely considered unpredictable, structured patterns persist. The backtesting results across 2020–2025 validate the core hypothesis.
UPSC is not random. 266 Hot Topics.
The result is not certainty. It is clarity, and in one of the world’s most competitive examinations, clarity is a real competitive advantage.
Every topic is ranked by confidence, backed by real news signals, and comes with UPSC-format practice questions.
Built for UPSC Prelims 2026.
Get Predictions on EdMe →
* Recall is measured as the fraction of actual exam topics that were present in EdMe’s predicted topic list for that year. Each year was evaluated as a blind prediction — the model was trained only on data available before that examination date.
Where:
- = set of actual topics that appeared in the exam
- = set of predicted topics overall, or in a specific bucket (High / Medium / Low)
Predictions are not guesses. They are signals.
Predictions — EdMe | AI Research · April 2026 · edmeapp.ai